
A.I. – zaczęło się od gier na Atari 2600 a skończyło wygraną z mistrzem świata w “GO” – historia z 500 mln dolarów w tle…
Po przerwie na ferie zimowe, wracamy do naszego dwutygodniowego cyklu wpisów na blogu. W międzyczasie z połowy stycznia zrobiła nam się połowa lutego, górskie szlaki narciarskie sprawiły się doskonale, a pogoda dopisała. Na moment wróciła prawdziwa zima, która jednak powoli blednie i kurczy się w swej białej pierzynie. Na niebie widać już wracające z południa klucze dzikich gęsi, których klangor dobitnie informuje nas o nadchodzącym przedwiośniu.  Dodatkowo dzisiaj rano nad moim domem przeleciała para żurawi (to te bez zagiętej szyi w locie 🙂 ), które najliczniej występują właśnie na Pomorzu Zachodnim. Relatywnie wysokie temperatury sprzyjają aktywności bobrów, które jednak w mojej okolicy poczyniły znaczne szkody w drzewostanie. Bóbr europejski jest jest największym naszym gryzoniem dorastającym do 110cm długości, a jego waga może dochodzić nawet do 29 kilogramów.
Dodatkowo dzisiaj rano nad moim domem przeleciała para żurawi (to te bez zagiętej szyi w locie 🙂 ), które najliczniej występują właśnie na Pomorzu Zachodnim. Relatywnie wysokie temperatury sprzyjają aktywności bobrów, które jednak w mojej okolicy poczyniły znaczne szkody w drzewostanie. Bóbr europejski jest jest największym naszym gryzoniem dorastającym do 110cm długości, a jego waga może dochodzić nawet do 29 kilogramów. 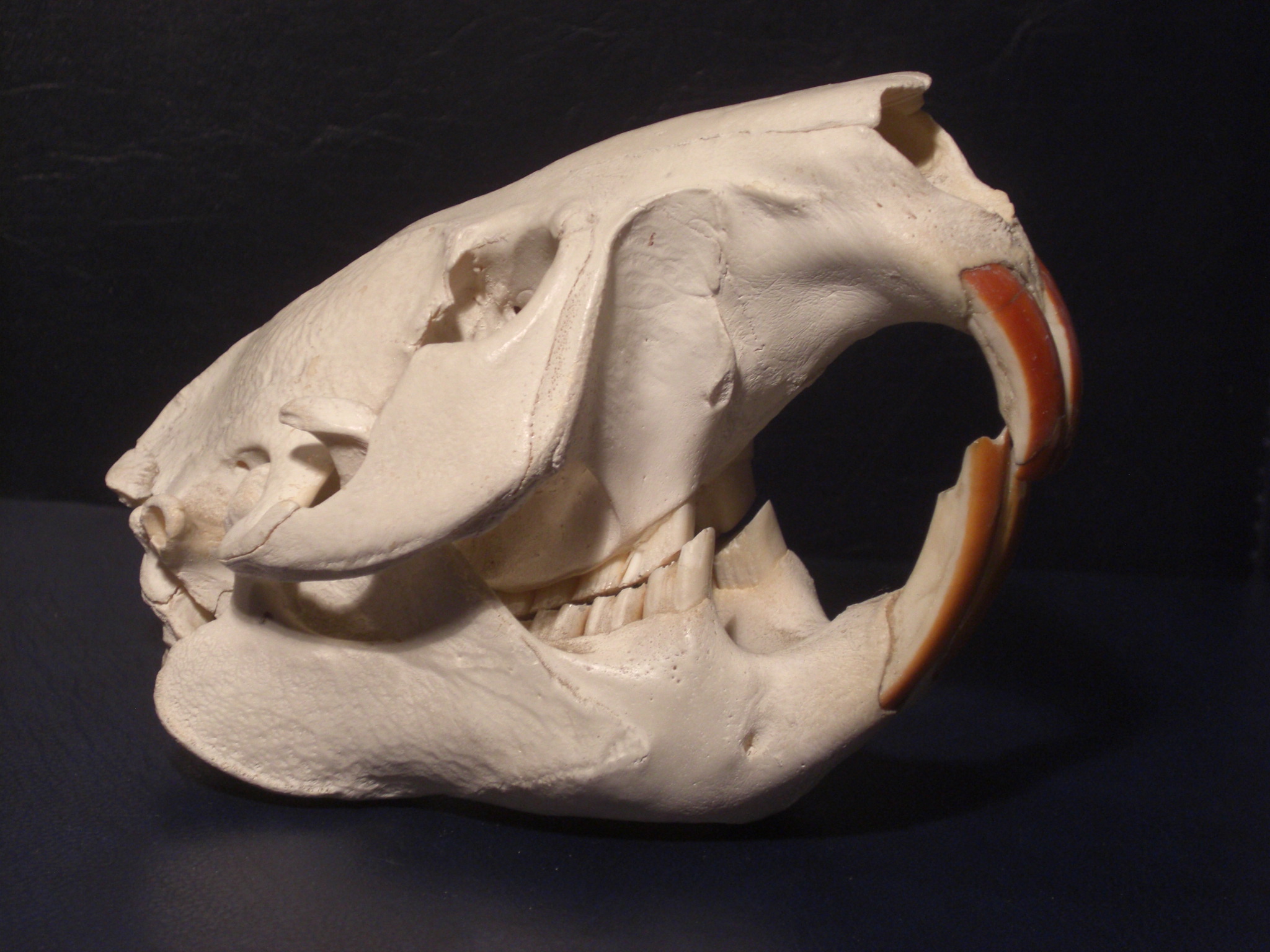 Tylne łapy wyposażone są w płetwy, a dodatkowo w pływaniu pomaga sporych rozmiarów spłaszczony ogon, który pełni także rolę termoregulacyjną i służy do magazynowania tłuszczu. Bóbr wiedzie nocny tryb życia, jest zwierzęciem monogamicznym i mocno terytorialnym. Potrafi dostosować środowisko do swoich potrzeb budując tamy i żeremia. Jego ogromne siekacze potrafią dać radę nawet drzewu o metrowej średnicy i rosną przez całe życie, co powoduje że muszą być regularnie ścierane.
Tylne łapy wyposażone są w płetwy, a dodatkowo w pływaniu pomaga sporych rozmiarów spłaszczony ogon, który pełni także rolę termoregulacyjną i służy do magazynowania tłuszczu. Bóbr wiedzie nocny tryb życia, jest zwierzęciem monogamicznym i mocno terytorialnym. Potrafi dostosować środowisko do swoich potrzeb budując tamy i żeremia. Jego ogromne siekacze potrafią dać radę nawet drzewu o metrowej średnicy i rosną przez całe życie, co powoduje że muszą być regularnie ścierane.  Co ciekawe diastema u bobra sięga 70% szerokości szczęki i chyba najlepsi stomatolodzy byliby tu bezradni. 😉 Ta diastema pozwala zasunąć wargi podczas nurkowania wokół szczęk pozostawiając siekacze na wierzchu. Bóbr jest doskonale przystosowany do ziemnowodnego trybu życia i potrafi pod wodą przebywać nawet do 15 minut bez zaczerpnięcia powietrza.
Co ciekawe diastema u bobra sięga 70% szerokości szczęki i chyba najlepsi stomatolodzy byliby tu bezradni. 😉 Ta diastema pozwala zasunąć wargi podczas nurkowania wokół szczęk pozostawiając siekacze na wierzchu. Bóbr jest doskonale przystosowany do ziemnowodnego trybu życia i potrafi pod wodą przebywać nawet do 15 minut bez zaczerpnięcia powietrza.  Futro bobra jest bardzo gęste, na 1 cm kwadratowym potrafi znajdować się nawet ponad 20 tysięcy włosów. Bobry żywią się wyłącznie pokarmem roślinnym i zazwyczaj żerują do 20 metrów od cieku wodnego. Zwierzęta te żyją w grupach rodzinnych, w skład których wchodzą rodzice i do 2 pokoleń młodych – zazwyczaj od 4 do 10 osobników. Trzyletnie bobry osłabiają więzi rodzinne i wyruszają na poszukiwanie partnerów i nowych żerowisk, często pokonując znaczne odległości.
Futro bobra jest bardzo gęste, na 1 cm kwadratowym potrafi znajdować się nawet ponad 20 tysięcy włosów. Bobry żywią się wyłącznie pokarmem roślinnym i zazwyczaj żerują do 20 metrów od cieku wodnego. Zwierzęta te żyją w grupach rodzinnych, w skład których wchodzą rodzice i do 2 pokoleń młodych – zazwyczaj od 4 do 10 osobników. Trzyletnie bobry osłabiają więzi rodzinne i wyruszają na poszukiwanie partnerów i nowych żerowisk, często pokonując znaczne odległości.  Szczyt aktywności bobrów przypada na jesienne przygotowania do zimy: budowę i naprawę nor i żeremi oraz gromadzenie zapasów na zimę. Jest to najbardziej widoczne w październiku. Na wiosnę natomiast przypada okres opieki nad nowo-narodzonymi członkami rodziny i przebywanie na jednym żerowisku do końca kwietnia. Co ciekawe nory bobrów są wielopiętrowe a ich łączna długość sięga 50 m. Żeremia natomiast stanowią konstrukcję sięgające nawet do 3 m wysokości o średnicy podstawy do 20 m. Bóbr to zwierzę o dużej inteligencji porównywalnej do inteligencji szczurów, żyjące do 30 lat. W Polsce jest gatunkiem częściowo chronionym, czyli dopuszcza się kontrolę i redukcję jego liczebności.
Szczyt aktywności bobrów przypada na jesienne przygotowania do zimy: budowę i naprawę nor i żeremi oraz gromadzenie zapasów na zimę. Jest to najbardziej widoczne w październiku. Na wiosnę natomiast przypada okres opieki nad nowo-narodzonymi członkami rodziny i przebywanie na jednym żerowisku do końca kwietnia. Co ciekawe nory bobrów są wielopiętrowe a ich łączna długość sięga 50 m. Żeremia natomiast stanowią konstrukcję sięgające nawet do 3 m wysokości o średnicy podstawy do 20 m. Bóbr to zwierzę o dużej inteligencji porównywalnej do inteligencji szczurów, żyjące do 30 lat. W Polsce jest gatunkiem częściowo chronionym, czyli dopuszcza się kontrolę i redukcję jego liczebności.
Czym dzisiaj się zajmiemy? Także inteligencją ale sztuczną, z której przejawami mieliśmy do czynienia niemal w każdej grze, gdzie przeciwnikiem był komputer. Jednak dopiero zastosowanie algorytmów sieci neuronowych spowodowało niesamowity postęp możliwości sztucznej inteligencji, aż do momentu gdy komputer był w stanie pokonać mistrza świata w jednej z najtrudniejszych gier, której liczba możliwości legalnych ruchów przekracza liczbę atomów we wszechświecie, a mianowicie w Go. Zanim jednak przejdziemy do tego tematu tradycyjnie szybki raport co dzieje się w ogrodzie. 🙂
 Rośliny na szczęście zwolniły wzrost z powodu mrozów. Ptaki nadal korzystają z ptasiego spa, powodując, iż zapasy słonecznika doszły do poziomu rezerwy i dzisiaj odebrałem z paczkomatu kolejne 10kg tego ptasiego przysmaku.
Rośliny na szczęście zwolniły wzrost z powodu mrozów. Ptaki nadal korzystają z ptasiego spa, powodując, iż zapasy słonecznika doszły do poziomu rezerwy i dzisiaj odebrałem z paczkomatu kolejne 10kg tego ptasiego przysmaku.  Kule tłuszczowe z właściwym sobie tempem sublimują. 😉 W ogrodzie dominują teraz sikorki wspomagane przez dzwońce, mazurki, a nawet parę sierpówek. Regularnie wykładane połówki jabłek ze smakiem spożywają kosy.
Kule tłuszczowe z właściwym sobie tempem sublimują. 😉 W ogrodzie dominują teraz sikorki wspomagane przez dzwońce, mazurki, a nawet parę sierpówek. Regularnie wykładane połówki jabłek ze smakiem spożywają kosy.  Dodatkowo to już czas najwyższy na wyczyszczenie budek lęgowych dla ptaków. Ja po oczyszczeniu wypalam je “żywym” ogniem 🙂 aby pozbyć się ptasich insektów i moszczę niedużą ilością suchej trawy. Tak, przygotowane niemal natychmiast zostaną zasiedlone; ciekawe jakie gatunki opanują w tym roku 4 budki znajdujące się w ogrodzie. Jeżeli planujecie umieszczenie kliku budek typu A (dla sikorek) w ogrodzie lub lesie to pamiętajcie, aby umieszczać je w odległości co najmniej 25m od siebie ponieważ sikorki są terytorialne. Polecam budki wg projektu przedwojennego ornitologa prof. Sokołowskiego.
Dodatkowo to już czas najwyższy na wyczyszczenie budek lęgowych dla ptaków. Ja po oczyszczeniu wypalam je “żywym” ogniem 🙂 aby pozbyć się ptasich insektów i moszczę niedużą ilością suchej trawy. Tak, przygotowane niemal natychmiast zostaną zasiedlone; ciekawe jakie gatunki opanują w tym roku 4 budki znajdujące się w ogrodzie. Jeżeli planujecie umieszczenie kliku budek typu A (dla sikorek) w ogrodzie lub lesie to pamiętajcie, aby umieszczać je w odległości co najmniej 25m od siebie ponieważ sikorki są terytorialne. Polecam budki wg projektu przedwojennego ornitologa prof. Sokołowskiego.  Ważne aby budki nie miały patyczka, który ułatwia drapieżnikom dostęp do gniazda i znajdowały się na odpowiedniej dla danego gatunku wysokości (dla sikorki: 2-3 m). Jeżeli planujecie je przybić do drzewa to polecam metodę na 2 gwoździe: jeden wbijamy do końca, a drugi zostawiamy z marginesem 1-2 cm, tak aby przyrastanie drzewa nie doprowadziło do oderwania się budki. Szczególnie istotne jest to w parkach i lasach, gdzie dostęp do budek jest utrudniony.
Ważne aby budki nie miały patyczka, który ułatwia drapieżnikom dostęp do gniazda i znajdowały się na odpowiedniej dla danego gatunku wysokości (dla sikorki: 2-3 m). Jeżeli planujecie je przybić do drzewa to polecam metodę na 2 gwoździe: jeden wbijamy do końca, a drugi zostawiamy z marginesem 1-2 cm, tak aby przyrastanie drzewa nie doprowadziło do oderwania się budki. Szczególnie istotne jest to w parkach i lasach, gdzie dostęp do budek jest utrudniony.  Budek nie malujemy, pozostawiamy naturalne drewno, pomalowanie ich np. pokostem lnianym zdecydowanie wyłączy budkę z użytku przynajmniej na jeden sezon. 🙂 Najlepszą stroną na przymocowanie budki jest strona wschodnia lub północna, unikamy strony południowej ze względu na potencjalne nagrzewanie i strony zachodniej ze względu na przeważające w naszej strefie wiatry zachodnie. No właśnie, zapomniałbym powiedzieć o psie, a tu moja przyjaciółka z Wielkopolski od razu zgłosiłaby reklamację. 😉 Pies ma się dobrze, wyglądem coraz bardziej przypomina wielką futrzaną kulę z czterema łapami, ogonem i wielkim nosem. 🙂 Dalej na służbie dzielnie pilnuje ptaków, jednak gdy jego skrzydlaci przyjaciele udają się w kierunku sosny koreańskiej, aby schronić się przed deszczem, pies uznaje to za fajrant i idzie do budy, aby nie moknąć i oddać się zasłużonej regeneracji w pozycji niskiego wydatku energetycznego, pozostając jednak w stałym nasłuchu, aby w razie konieczności w 3 sekundy dobiec do miejsca potencjalnego zakłócenia porządku. 😉
Budek nie malujemy, pozostawiamy naturalne drewno, pomalowanie ich np. pokostem lnianym zdecydowanie wyłączy budkę z użytku przynajmniej na jeden sezon. 🙂 Najlepszą stroną na przymocowanie budki jest strona wschodnia lub północna, unikamy strony południowej ze względu na potencjalne nagrzewanie i strony zachodniej ze względu na przeważające w naszej strefie wiatry zachodnie. No właśnie, zapomniałbym powiedzieć o psie, a tu moja przyjaciółka z Wielkopolski od razu zgłosiłaby reklamację. 😉 Pies ma się dobrze, wyglądem coraz bardziej przypomina wielką futrzaną kulę z czterema łapami, ogonem i wielkim nosem. 🙂 Dalej na służbie dzielnie pilnuje ptaków, jednak gdy jego skrzydlaci przyjaciele udają się w kierunku sosny koreańskiej, aby schronić się przed deszczem, pies uznaje to za fajrant i idzie do budy, aby nie moknąć i oddać się zasłużonej regeneracji w pozycji niskiego wydatku energetycznego, pozostając jednak w stałym nasłuchu, aby w razie konieczności w 3 sekundy dobiec do miejsca potencjalnego zakłócenia porządku. 😉
 Raport ogrodowy mamy zaliczony, szykujcie zatem aromatyczną kawę i jeżeli jej ziarna zostały już poddane obróbce cieplnej, a Wasza pozycja zapewnia należyty komfort termiczny i ortopedyczny jej spożywania to możemy zaczynać! 😉
Raport ogrodowy mamy zaliczony, szykujcie zatem aromatyczną kawę i jeżeli jej ziarna zostały już poddane obróbce cieplnej, a Wasza pozycja zapewnia należyty komfort termiczny i ortopedyczny jej spożywania to możemy zaczynać! 😉
***

Czym jest sztuczna inteligencja? Czym różni się od inteligencji naturalnej? Termin sztucznej inteligencji (ang. Artificial Intelligence – A.I.) po raz pierwszy użyty został przez Johna McCarthy’ego w 1956 roku. John McCarthy zaangażowany był m.in. w korespondencyjny pojedynek szachowy pomiędzy sowieckim a amerykańskim komputerem, który odbył się na przełomie lat 1966-67. W informatyce sztuczna inteligencja oznacza algorytmy symulujące zachowania chociaż częściowo inteligentne. Dzisiejsze znaczenie określenia “sztuczna inteligencja” to próba osiągnięcia na poziomie technicznym inteligencji porównywalnej z naturalną, a szczególnie z umysłem człowieka. Dotyczy to przede wszystkim zadań, gdzie algorytmy numeryczne nie są w stanie sobie poradzić lub jest to bardzo trudne. Do tych zadań należą m.in. systemy eksperckie i diagnostyczne, inteligentne roboty, a także gry logiczne takie jak szachy i Go. W szachach komputer był w stanie pokonać mistrza świata Garriego Kasparowa już w 1997 roku. W Go sytuacja wyglądała inaczej. Ilość możliwych kombinacji sięgająca aż 2.1*10^170 czyli 10^100 razy więcej niż w szachach nie pozwalała na opracowanie programu grającego na poziomie mistrzowskim. W szachach liczba możliwych ruchów w danej sytuacji sięga zazwyczaj liczby 20, natomiast w Go jest to aż 200. Gdyby zebrać wszystkie dostępne na świecie komputery i pozwolić im pracować przez milion lat, to i tak nie byłaby to wystarczająca moc obliczeniowa, aby obliczyć wszystkie możliwe posunięcia w Go metodą siłowej analizy (ang. brute-force). Dlatego też Go stało się świętym graalem dla systemów sztucznej inteligencji. Sam Einstein stwierdził, że Go jest zbyt skomplikowane, aby dało się utworzyć system teoretyczny tej gry. Dopiero pojawienie się algorytmów samouczących (ang. machine learning) symulujących zachowanie ludzkich sieci neuronowych dało pewną nadzieję na poprawę sytuacji. A zatem zacznijmy od początku. 🙂
![]() W roku 2010 powstaje w Wielkiej Brytanii startup DeepMind założony przez Demisa Hassabisa,
W roku 2010 powstaje w Wielkiej Brytanii startup DeepMind założony przez Demisa Hassabisa,
Shane’a Legg’a i Mustafę Suleymana. Firma rozpoczęła prace nad systemem głębokich sieci neuronowych (ang. Deep Neural Network), które byłby w stanie grać w gry komputerowe z lat 70-tych i 80-tych podobnie jak robił to człowiek. Wybór padł na gry z konsoli Atari VCS/2600 ponieważ stopień ich skomplikowania jest znacznie mniejszy niż gry, które powstają dzisiaj. Na tapetę poszły takie tytuły jak:

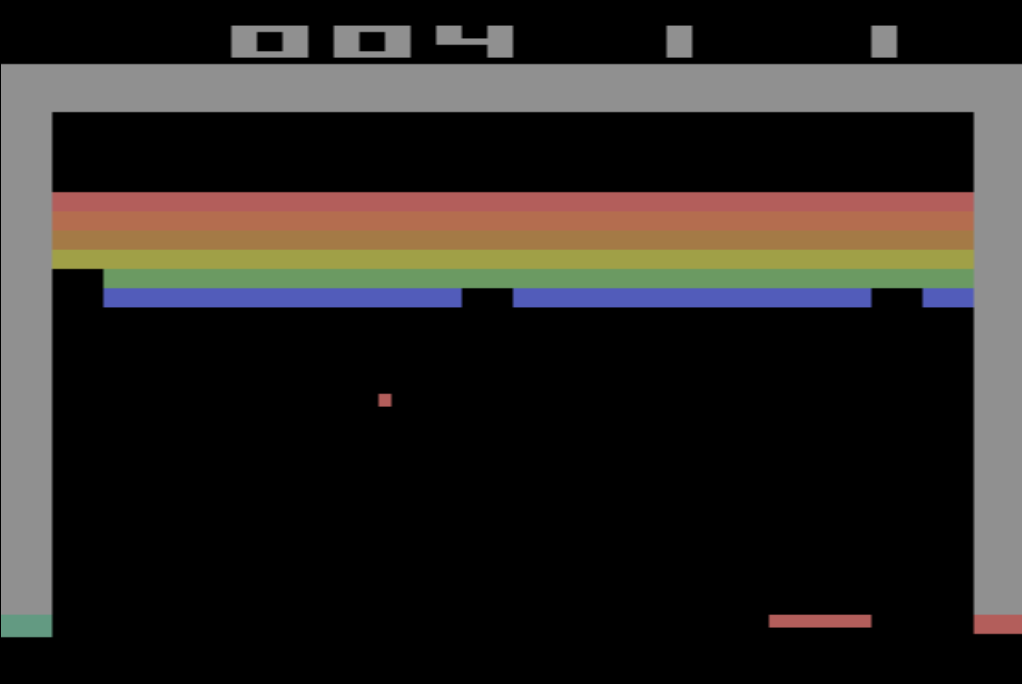


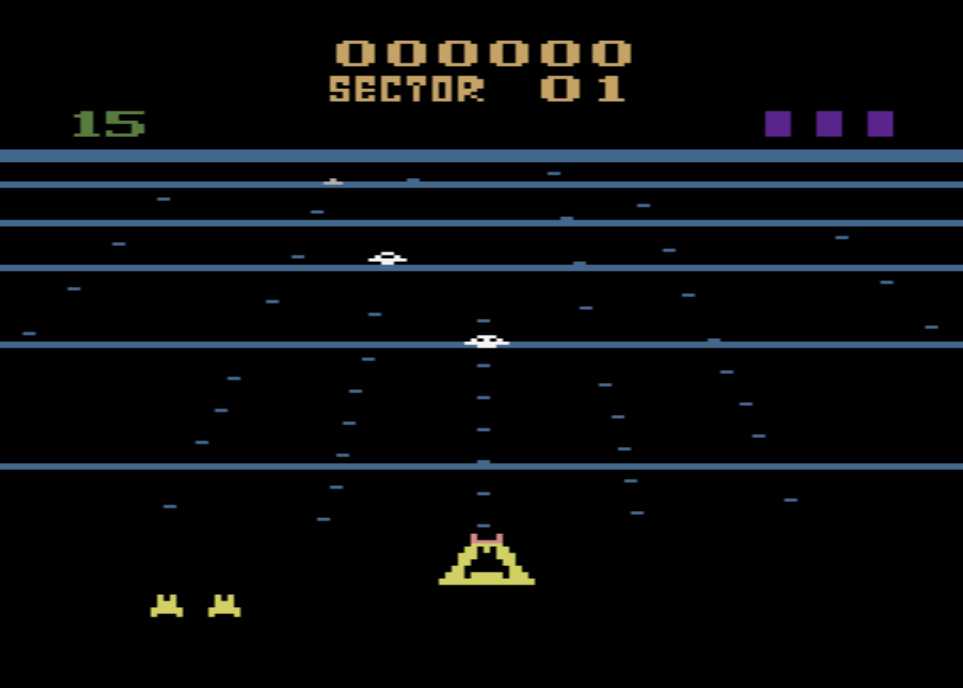
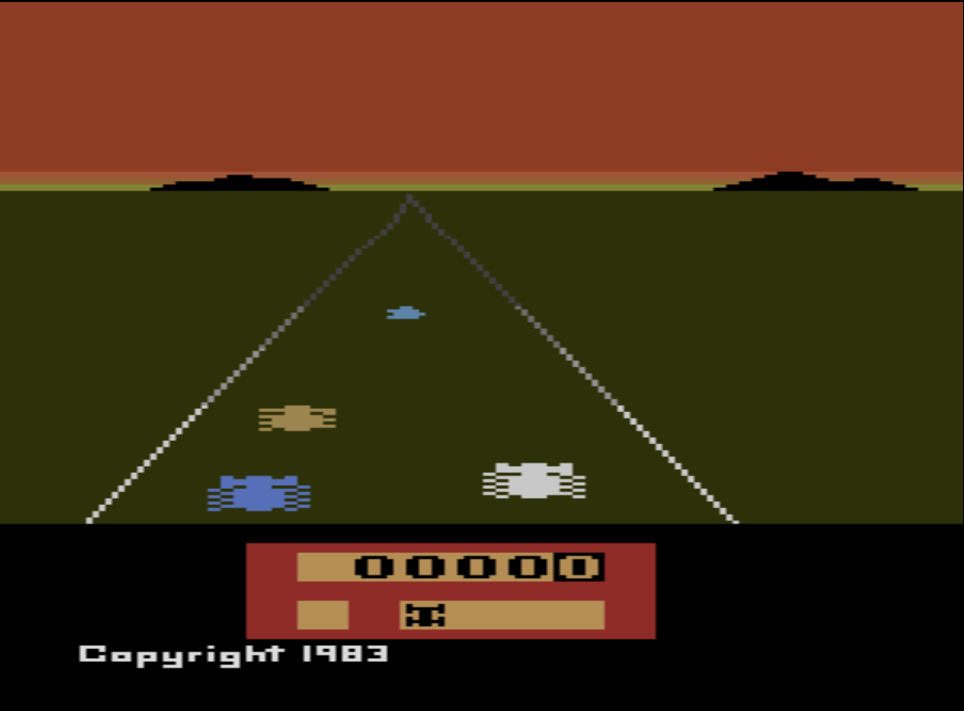

System wykorzystywał konwolucyjne sieci neuronowe, które wykorzystywane są np. do rozpoznawania obrazów wraz z mechanizmem uczenia maszynowego Q-learning będącym rodzajem uczenia się przez wzmacnianie (ang. reinforcement learning). Działa to podobnie jak w przypadku naszego umysłu i umysłu większości zwierząt. Nie znając zasad uczymy się ich poprzez wzmacnianie za pomocą nagrody. Im częściej dostajemy nagrodę, tym szybciej uczymy się jak ją osiągnąć, zapamiętując określone algorytmy prowadzące do sukcesu. Podobnie w przypadku systemu opracowanego przez DeepMind, nazwanego Deep Q Networks (DQN), program odczytywał obraz z Atari 2600 o rozdzielczości 210×160 nie znając kompletnie zasad tych gier. Ponieważ systemy punktowe gier bardzo się od siebie różniły dokonano ich normalizacji otrzymując wartości nagrody +1, 0, -1. System grając w poszczególne gry dążył do uzyskania jak największej liczby nagród, wzmacniając i utrwalając swoje decyzje ich osiąganiem. Te nagrody przekładały się na większą ilość osiągniętych punktów w poszczególnych grach w ramach postępu procesu uczenia się. Eksperyment zakończył się następującymi średnimi wynikami punktowymi przeprowadzonych rozgrywek:
| gracz | Breakout | Enduro | Pong | B.Rider | Q*Bert | Seaquest | Space Inv. |
| A.I. (DQN) | 168 | 470 | 20 | 4092 | 1952 | 1705 | 581 |
| człowiek | 31 | 368 | -3 | 7456 | 18900 | 28010 | 3690 |
W przypadku 3 pierwszych od lewej gier system DQN osiągnął zdecydowanie lepsze rezultaty niż gracz na poziomie eksperckim. W przypadku gry Beam Rider człowiek osiągnął dwukrotnie lepszy wynik, natomiast w przypadku gier Q*Bert, Seaquest i Space Invaders system sztucznej inteligencji wypadł zdecydowanie gorzej od człowieka i było to związane z tym, że właśnie te gry dla sieci neuronowych okazały się bardziej wymagające, gdyż konieczne było nauczenie się i zastosowanie strategii długofalowej. Widać, iż z tym rodzajem zadań system sztucznej inteligencji DeepMind w tamtym momencie radził sobie gorzej. Zobaczcie jak DQN uczył się grać w Breakout i do jakich wyników doszedł w zależności od liczby rozegranych gier, przypominam, że system nie znał kompletnie zasad tej gry, nie wiedział co to piłka, jak zdobywać punkty etc.:
Robi wrażenie? 🙂 Zdecydowanie! A to był zaledwie rok 2013. Co działo się dalej?

W roku 2014 DeepMind został kupiony przez Google za sumę 500 mln dolarów (!). W tym samym roku DeepMind został “firmą roku” w ramach plebiscytu organizowanego przez Uniwersytet Cambridge. Prace nad sztuczną inteligencją trwały dalej, firma postawiła sobie za zadanie zrozumienie jak działa inteligencja i zaimplementowanie jej w urządzeniach technicznych. Go było doskonałym do tego wyzwaniem i jak stwierdził Demis Hassabis, prezes i jeden z założycieli DeepMind zadanie to odpowiadało wysiłkowi związanemu z programem Apollo, tyle że odnosiło się do sztucznej inteligencji. Po dwóch latach pracy nad AlphaGo program był gotowy do gry z mistrzem Go. Wybór padł na profesjonalnego gracza Fan Hui (poziom 2p czyli drugi profesjonalny dan) będącego mistrzem Europy w Go.  Mieszkający we Francji Fan Hui otrzymał e-mail od Demisa z informacją, że pracują nad interesującym projektem dotyczącym Go i chcieliby się tym faktem podzielić i zaprosić Fan Hui do Londynu. Fan Hui zgodził się przewidując, że zostanie podłączony do jakiejś maszyny analizującej jego sposób myślenia, gry etc., jednak fakty były inne, chciano aby zmierzył się z programem komputerowym AlphaGo. Fan Hui, zgodził się myśląc, że to tylko program i że to nie będzie specjalnie trudne zadanie. Zgodził się także aby można było sfilmować ten pojedynek, który miał składać się z 5 partii Go.
Mieszkający we Francji Fan Hui otrzymał e-mail od Demisa z informacją, że pracują nad interesującym projektem dotyczącym Go i chcieliby się tym faktem podzielić i zaprosić Fan Hui do Londynu. Fan Hui zgodził się przewidując, że zostanie podłączony do jakiejś maszyny analizującej jego sposób myślenia, gry etc., jednak fakty były inne, chciano aby zmierzył się z programem komputerowym AlphaGo. Fan Hui, zgodził się myśląc, że to tylko program i że to nie będzie specjalnie trudne zadanie. Zgodził się także aby można było sfilmować ten pojedynek, który miał składać się z 5 partii Go.  Już po pierwszej partii Fan Hui zdał sobie sprawę, że nie jest to zwykły program. Pierwsza rozgrywka po popełnieniu błędu skończyła się porażką mistrza Europy. W drugiej partii starał się on zmienić swój styl gry jednak i ją przegrał. Podobnie było w trzeciej, czwartej i piątej partii. Fan Hui przegrał pojedynek 0-5. AlphaGo triumfował. Był to październik 2015 roku i pierwszy przypadek, kiedy profesjonalny gracz Go przegrał z komputerem.
Już po pierwszej partii Fan Hui zdał sobie sprawę, że nie jest to zwykły program. Pierwsza rozgrywka po popełnieniu błędu skończyła się porażką mistrza Europy. W drugiej partii starał się on zmienić swój styl gry jednak i ją przegrał. Podobnie było w trzeciej, czwartej i piątej partii. Fan Hui przegrał pojedynek 0-5. AlphaGo triumfował. Był to październik 2015 roku i pierwszy przypadek, kiedy profesjonalny gracz Go przegrał z komputerem.
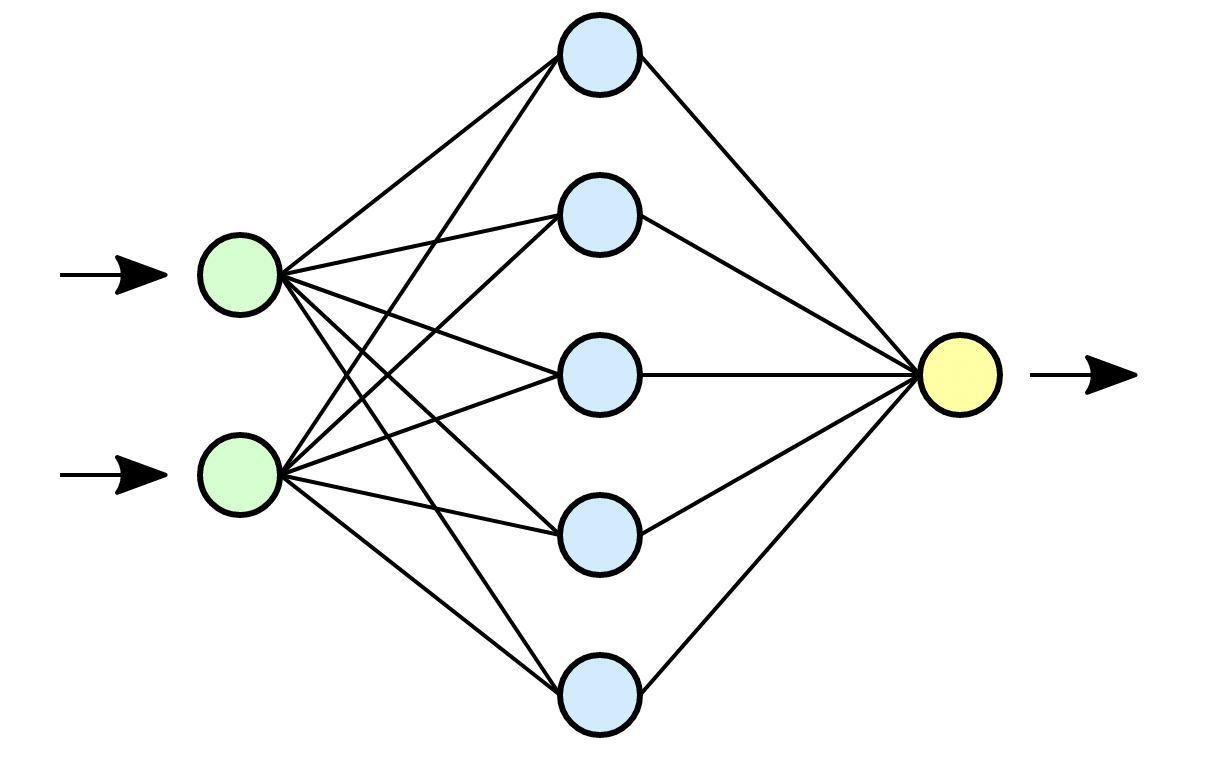
Jak zbudowany był system AlphaGo? Składał się z dwóch głębokich sieci neuronowych wspomaganych metodą wyszukiwania MonteCarlo (MCTS – MonteCarlo Tree Search) skupiającą się, tak jak podaje Wikipedia, na “analizie najbardziej obiecujących ruchów, opierając rozrost drzewa wariantów na losowym próbkowaniu przestrzeni przeszukiwań”. 🙂 Pierwsza sieć nazwana “value network” oceniała aktualną pozycję i przewidiwała zwycięzcę, druga sieć nazwana “policy network” analizowała jaki najlepszy ruch można wykonać. Proces uczenia sieci neuronowych polegał początkowo na pobraniu z Internetu 100.000 rozgrywek wykonanych przez graczy tak, aby system mógł naśladować grę człowieka. Następnie system rozpoczął rozgrywkę z samym sobą wykonując miliony pojedynków, tak aby uczyć się metodą wzmocnienia na własnych błędach i sukcesach. Mieliśmy więc tu do czynienia z głębokimi sieciami neuronowymi, dużą ilością danych (ang. big-data) i uczeniem maszynowym (ang. Machine Learning).
Po meczu na Fan Hui spadła fala krytyki, szczególnie w jego rodzinnych Chinach. Zarzucano mu, że za długo przebywa w Europie i pewnie dlatego poziom jego gry nie jest najwyższy. Odpowiedzią na te zarzuty miał być kolejny mecz AlphaGo zaplanowany w dniach: 9-15 marca 2016 roku, tym razem z dominującym od 10-lat mistrzem świata – Koreańczykiem Lee Sedol’em (9-ty najwyższy profesjonalny dan), znanym z kreatywnego i agresywnego sposobu gry. W wywiadzie przed spotkaniem, Lee Sedol był pewien wygranej, stwierdził że poziom Fan Hui był niższy niż jego, a przez tych 5 miesięcy od pojedynku z Fan Hui AlphaGo nie miał szans na znaczne poprawienie swojej gry. Przewidywał wynik 5-0 na swoją korzyść lub co najwyżej 4-1.

Zespół DeepMind nie zasypiał jednak gruszek w popiele. System otrzymywał nowe dane, sieci neuronowe były dalej szkolone, a jako konsultant został powołany właśnie Fan Hui, który grając przez całe dni z AlphaGo wskazywał jego potencjalne słabości.
9 marca 2016 roku w hotelu w Seulu rozpoczął się historyczny pojedynek. Pierwszą walkę wygrał AlphaGo. Było to szokiem dla społeczności Go i dla samego Lee Sedola. Drugi i trzeci pojedynek, również wyglądał podobnie. W czwartym pojedynku AlphaGo się poddał. Piąty pojedynek znowu należał do AlphaGo. Cały mecz zakończył się wygraną AlphaGo 4-1. Był to przełomowy moment w historii Go, w historii komputerów a także myśle, że w historii ludzkości. Komputer wygrał nie tylko z ludzkim intelektem, ale także z ludzką intuicją. Jeżeli jesteście zainteresowani szczegółami tego pojedynku polecam doskonały, wielokrotnie nagrodzony film dokumentalny, dostępny za darmo:
AlphaGo podlegał dalszemu rozwojowi. DeepMind opracowywał kolejne wersje systemu idąc w kierunku głębokiego samouczenia się systemu startującego już bez danych początkowych, podobnie jak to ma miejsce w przypadku niemowlęcia, uczącego się metodą poznawczą.
| Rok | System | Go | szachy | Shogi | Atari 2600 | szkolenie przez człowieka | wiedza domenowa | zasady |
| 2016 | AlphaGo | x | x | x | x | |||
| 2017 | AlphaGo Zero | x | x | |||||
| 2018 | AlphaZero | x | x | x | x | |||
| 2020 | MuZero | x | x | x | x |
A co się stało z umiejętnościami sztucznej inteligencji związanymi z naszym Atari 2600? Od czasu powstania DQN społeczność zajmująca się sztuczną inteligencją opracowała wiele systemów bazujących na metodzie uczenia się przez wzmacnianie (ang. deep reinforcement learning) i testowała je w środowisku ALE (ang. Arcade Learning Environment), które oferuje miejsce do uczenia systemów sztucznej inteligencji i eksperymentowania z grami z Atari 2600. Niestety żaden z tych systemów nie był w stanie poradzić sobie z następującymi grami: Montezuma’s Revenge, Pitfall, Solaris i Skiing. Jednak po znacznym rozbudowaniu oryginalnego systemu DQN, dodaniu adaptacyjnego systemu wyboru podejścia przy uczeniu się i graniu w zależności od typu gry (gry zręcznościowe, gdzie rezultat jest natychmiastowy – expoitative policy i ekspolarycjne, gdzie wynik pojawia się dopiero po pewnym czasie – exploratory policy) system “Agent57” od DeepMind był w 2020 roku w stanie i z tymi grami sobie poradzić oraz generalnie przekroczyć poziom człowieka w 57 grach dla Atari 2600. Poniżej przykład jak poradził sobie z Solarisem:
“Agent 57” uzyskał dla wszystkich 57 gier wynik średni lepszy niż najlepsi gracze (120% – gdzie 100% odpowiada człowiekowi-ekspertowi). Drugi wynik osiągnięty został wcześniej przez inny program – NGU (Never Give Up) – ponad 60% i przekroczył poziom człowieka dla 51 gier, a na trzecim miejscu znalazł się bardzo swojsko brzmiący R2D2 z wynikiem na poziomie 50% i przekroczeniu poziomu człowieka dla 52 gier. Wspomniany wcześniej MuZero, pomimo iż osiągnął najwyższe wartości punktów w wielu grach np. kosmiczny wynik – 27.469% w grze “Beam Rider”: potrafił równocześnie całkowicie przegrać z człowiekiem w grach takich jak “Venture”. Dlatego też nie był w stanie wyprzedzić swoich konkurentów.
W poprzednim wpisie obiecałem Wam, że sprawdzę czy w czasach retrokomputerów nie pojawił się jakiś program do gry w GO na popularnej w Japonii platformie MSX. Otóż znalazłem pewien tytuł, wydany w 1987 przez Champion Soft: “TumeGo 120”. Niestety z powodu bariery językowej nie byłem w stanie za bardzo się tu zadomowić. Program jak nazwa “Tumego” może sugerować, chociaż jest błędnie zapisana po angielsku, jest zestawem puzzli GO, czyli tzw. “Tsumego – 詰碁” z układami “żywy-martwy” do rozwiązania. Tego typu układy były nawet publikowane w prasie, coś na kształt naszych “szachowych problemów do rozwiązania”. 🙂
 Jeżeli szukacie możliwości nauczenia się Go polecam aplikację mobilną, gdzie w wersji bezpłatnej zarówno nauczycie się podstaw jak i będziecie mieli możliwość pogrania ze sztuczną inteligencją oraz z innymi graczami na świecie (ja obecnie toczę korespondencyjny pojedynek z zawodnikiem z Korei Południowej). 🙂 Osobom zainteresowanym tematem “Deep Learning” polecam stronę DeepMind – znajdziecie tam mnóstwo materiałów m.in. artykuły z Nature, opisy matematyczne zastosowanych algorytmów, wykłady i ciekawe nowe zastosowania oraz dalsze kierunki rozwoju.
Jeżeli szukacie możliwości nauczenia się Go polecam aplikację mobilną, gdzie w wersji bezpłatnej zarówno nauczycie się podstaw jak i będziecie mieli możliwość pogrania ze sztuczną inteligencją oraz z innymi graczami na świecie (ja obecnie toczę korespondencyjny pojedynek z zawodnikiem z Korei Południowej). 🙂 Osobom zainteresowanym tematem “Deep Learning” polecam stronę DeepMind – znajdziecie tam mnóstwo materiałów m.in. artykuły z Nature, opisy matematyczne zastosowanych algorytmów, wykłady i ciekawe nowe zastosowania oraz dalsze kierunki rozwoju.
***
Kończąc chciałbym podzielić się pewną osobistą refleksją. Technika i wynalazki idą naprzód czy tego chcemy czy nie. Oczywiście powstaje problem etyczny w odniesieniu do tego, do czego wykorzystamy sztuczną inteligencję, a do czego nie. Powstały już organizacje mające na celu uregulowanie tych kwestii. Postępu jednak nie zatrzymamy i wiele dzisiejszych zawodów zniknie. Podam tu przykład windziarzy. Pomimo że już na początku 20 wieku Otis dysponował technologią umożliwiającą autonomiczną pracę wind, potrzeba było aż 40 lat i strajku windziarzy w USA, aby wchodzący po schodach w drapaczach chmur ludzie doszli do wniosku, że coś z tym trzeba zrobić. Wprowadzono systemy autonomiczne i pomimo, że wielu wieszczyło serię wypadków okazało się, że jest taniej i bezpieczniej, a zawód windziarza zniknął. Podobnie jest w przypadku sztucznej inteligencji, wcześniej czy później zdominuje pewne dziedziny i spowoduje, że uczące się dzisiejszych zawodów dzieci, będą musiały zmieniać zawód kilkakrotnie lub pracować w zawodach, które jeszcze dzisiaj są nieznane. Tym bardziej z ubolewaniem patrzę na nasze szkoły, w których poza wprowadzeniem testów i utratą autorytetu przez nauczycieli niewiele zmieniło się przez ostatnie 50 lat. Nadal uczymy dzieci tego samego kanonu lektur i staramy się przekonać, że Boryna nie był kobietą. 😉 Nota bene uważam za bardzo odważny eksperyment socjologiczny aby dać tę powieść do czytania dzisiejszej młodzieży, no cóż jak kiedyś pewien mądry człowiek we Francji stwierdził – nic tak nie zniechęca do czytania jak kanon lektur szkolnych. 😉  Tłamsimy niezależne myślenie, potrzebę dyskusji naturalną wśród młodych ludzi, a uczniów ponadprzeciętnych sprowadzamy do poziomu średniej, bo tylko problem z takimi uczniami. Przypomina to działanie w przypadku wystającego gwoździa, co z nim zazwyczaj robimy…wbijamy do poziomu deski. Potrafimy wypisywać idiotyczne uwagi w stylu “uczeń je na lekcji” albo “śpiewa na lekcji muzyki niepytany”, a jedynym wyznacznikiem wiedzy jest ocena. Uczymy dzieci pod kątem jak najlepszego zdania matury czyli jak poradzić sobie z systemem, zamiast ten chory system zmienić. Dodatkowo nikt nie uczy dzieci jak skutecznie się uczyć oraz jak współpracować w grupie przy realizacji wspólnego projektu. Świat się zmienił, mamy dostęp do ogromnej ilości informacji i zapamiętywanie dat na lekcji historii nie ma sensu. Lepiej nauczyć dzieci jak w tym chaosie informacyjnym oddzielić rzetelne informacje od manipulacji i dlaczego doszło do bitwy pod Grunwaldem oraz jakie były jej skutki, zamiast tego, że miała ona miejsce dokładnie w 1410 roku. No ale skoro tak uczono nasze pokolenie to przekazujemy bezrefleksyjnie ten anachroniczny system nauczania dalej. Młodzież nierzadko rozpoczyna lekcje o godzinie 7:00, gdzie psychologowie doskonale wiedzą, że nastolatek zaczyna w miarę dobrze funkcjonować około godziny 10:00. Wydajemy także ogromne pieniądze na korepetycje, zamiast oczekiwać od szkoły, która nasze dzieci uczy, aby te korepetycje nie były potrzebne. Ci sami nauczyciele, którzy nie są w stanie nauczyć uczniów w ramach systemu edukacji, po godzinach za dodatkową opłatą są jednak w stanie to zrobić… Nie lepiej jest także na uczelniach, na których nierzadko profesorowie uczą tego, czego sami nauczyli się 30 lat temu, a dodatkowo nie potrafią przekazywać wiedzy, gdyż poziom ich zdolności prezentacyjnych nie jest najwyższej próby. Na pewno pamiętacie nudne wykłady, gdzie zamiast zainteresowania problemem, podejścia od ogółu do szczegółu, podawano suche wzory bez jakiegokolwiek wyjaśnienia czy umocowania w otaczającym nas świecie, a elementem starającym się rozpaczliwie zwiększyć frekwencję na śmiertelnie nudnym wykładzie była lista obecności, kluczowa przy zaliczeniu. Obowiązywała w takim przypadku zasada 3xZ – Zakuć, Zaliczyć, Zapomnieć. Były oczywiście wyjątki i na takich wykładach zawsze był komplet, a coś takiego jak lista obecności nie przychodziło nawet wykładowcy na myśl. Wspominając śmiejemy się z tego…no ale czy nie jest to tak naprawdę śmiech przez łzy i może czas coś z tym zrobić? Polecam zerknąć jak działa fiński system edukacji i jakie ma wyniki… Świat pędzi dalej, czy tego chcemy czy nie i od tego jak przygotujemy do niego nasze dzieci zależy naprawdę bardzo wiele. Tyle osobistych refleksji 🙂 Życzę Wam udanego tygodnia i dobrej pogody! 🙂
Tłamsimy niezależne myślenie, potrzebę dyskusji naturalną wśród młodych ludzi, a uczniów ponadprzeciętnych sprowadzamy do poziomu średniej, bo tylko problem z takimi uczniami. Przypomina to działanie w przypadku wystającego gwoździa, co z nim zazwyczaj robimy…wbijamy do poziomu deski. Potrafimy wypisywać idiotyczne uwagi w stylu “uczeń je na lekcji” albo “śpiewa na lekcji muzyki niepytany”, a jedynym wyznacznikiem wiedzy jest ocena. Uczymy dzieci pod kątem jak najlepszego zdania matury czyli jak poradzić sobie z systemem, zamiast ten chory system zmienić. Dodatkowo nikt nie uczy dzieci jak skutecznie się uczyć oraz jak współpracować w grupie przy realizacji wspólnego projektu. Świat się zmienił, mamy dostęp do ogromnej ilości informacji i zapamiętywanie dat na lekcji historii nie ma sensu. Lepiej nauczyć dzieci jak w tym chaosie informacyjnym oddzielić rzetelne informacje od manipulacji i dlaczego doszło do bitwy pod Grunwaldem oraz jakie były jej skutki, zamiast tego, że miała ona miejsce dokładnie w 1410 roku. No ale skoro tak uczono nasze pokolenie to przekazujemy bezrefleksyjnie ten anachroniczny system nauczania dalej. Młodzież nierzadko rozpoczyna lekcje o godzinie 7:00, gdzie psychologowie doskonale wiedzą, że nastolatek zaczyna w miarę dobrze funkcjonować około godziny 10:00. Wydajemy także ogromne pieniądze na korepetycje, zamiast oczekiwać od szkoły, która nasze dzieci uczy, aby te korepetycje nie były potrzebne. Ci sami nauczyciele, którzy nie są w stanie nauczyć uczniów w ramach systemu edukacji, po godzinach za dodatkową opłatą są jednak w stanie to zrobić… Nie lepiej jest także na uczelniach, na których nierzadko profesorowie uczą tego, czego sami nauczyli się 30 lat temu, a dodatkowo nie potrafią przekazywać wiedzy, gdyż poziom ich zdolności prezentacyjnych nie jest najwyższej próby. Na pewno pamiętacie nudne wykłady, gdzie zamiast zainteresowania problemem, podejścia od ogółu do szczegółu, podawano suche wzory bez jakiegokolwiek wyjaśnienia czy umocowania w otaczającym nas świecie, a elementem starającym się rozpaczliwie zwiększyć frekwencję na śmiertelnie nudnym wykładzie była lista obecności, kluczowa przy zaliczeniu. Obowiązywała w takim przypadku zasada 3xZ – Zakuć, Zaliczyć, Zapomnieć. Były oczywiście wyjątki i na takich wykładach zawsze był komplet, a coś takiego jak lista obecności nie przychodziło nawet wykładowcy na myśl. Wspominając śmiejemy się z tego…no ale czy nie jest to tak naprawdę śmiech przez łzy i może czas coś z tym zrobić? Polecam zerknąć jak działa fiński system edukacji i jakie ma wyniki… Świat pędzi dalej, czy tego chcemy czy nie i od tego jak przygotujemy do niego nasze dzieci zależy naprawdę bardzo wiele. Tyle osobistych refleksji 🙂 Życzę Wam udanego tygodnia i dobrej pogody! 🙂


Zobacz również

C64 – od tego się zaczęło, wywiad z Liderem zespołu KOMBI Sławomirem Łosowskim…

Unofficial Atari History – nieoficjalnie o Atari…z Irlandii
